
How should the humanities leverage LLMs?
> Domain-specific pretraining!
Pretraining models can be a research tool, it's cheaper than LoRA, and allows studying
- grammatical change
- emergent word senses
- and who knows what more…
Train on your data with our pipeline or use ours!
#AI #LLM #linguistics
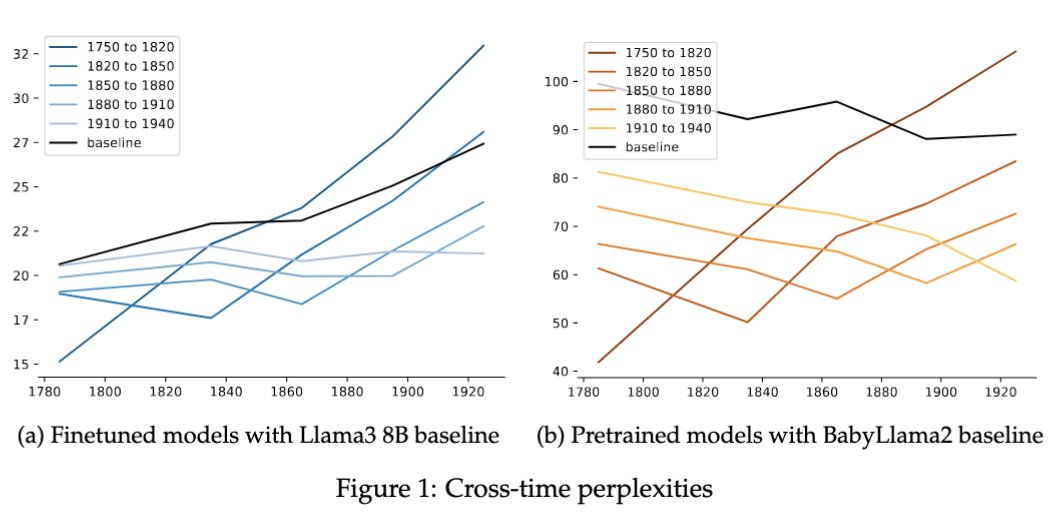
Typical Large Language Models (LLMs) are trained on massive, mixed datasets, so the model's behaviour can't be linked to a specific subset of the pretraining data. Or in our case, to time eras.
Historical analysis is a good example, as historical periods can get lost in blended information from different eras. Finetuning large models isn't enough, they “leak” future/modern concepts, making historical analysis impossible. Did you know cars existed in the 1800s? 


But what if we pretrain instead? You can get a unique LLM trained on small time corpora (10M tokens).
“Are you crazy? It will be so costly”
Oh no, it is even more efficient than training those monster LoRAs.

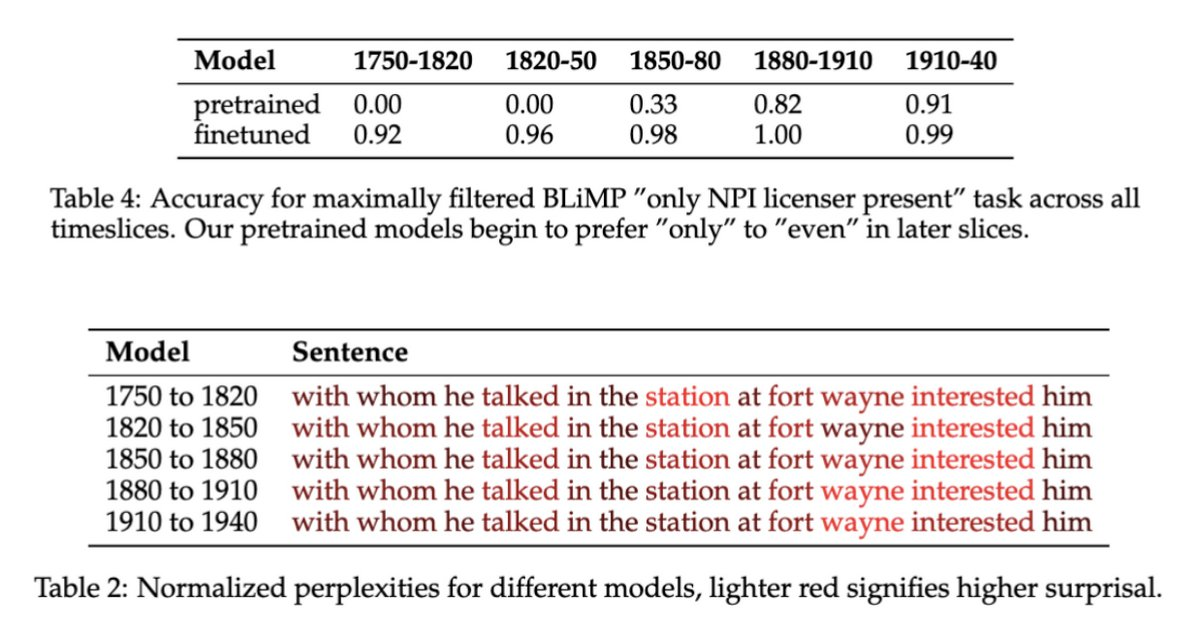
Using pretraining, we are able to track historical shifts, like evolving negative polarity item patterns in "only...ever" and "even...ever" - something not seen in the finetuned models.
It was also cool to explore word sense change, using simple differences in surprisal metrics.
Read more or use:
https://arxiv.org/abs/2504.05523
https://huggingface.co/Hplm