
I’m eager to read an ICLR paper discussing whether an LLM trained to "play" Othello learned a model of the board, not just surface statistics. But I’m immediately wary, based on a blog post by the lead author, who wrote: "the recent increase in model and data size has brought about qualitatively new behaviors such as writing basic code[1] or solving logic puzzles[2]."
The co-host of Mystery AI Hype Theatre 3000, @emilymbender, reminds us to "always read the footnotes" — these ones have issues!
First, here is the blog post: https://thegradient.pub/othello/
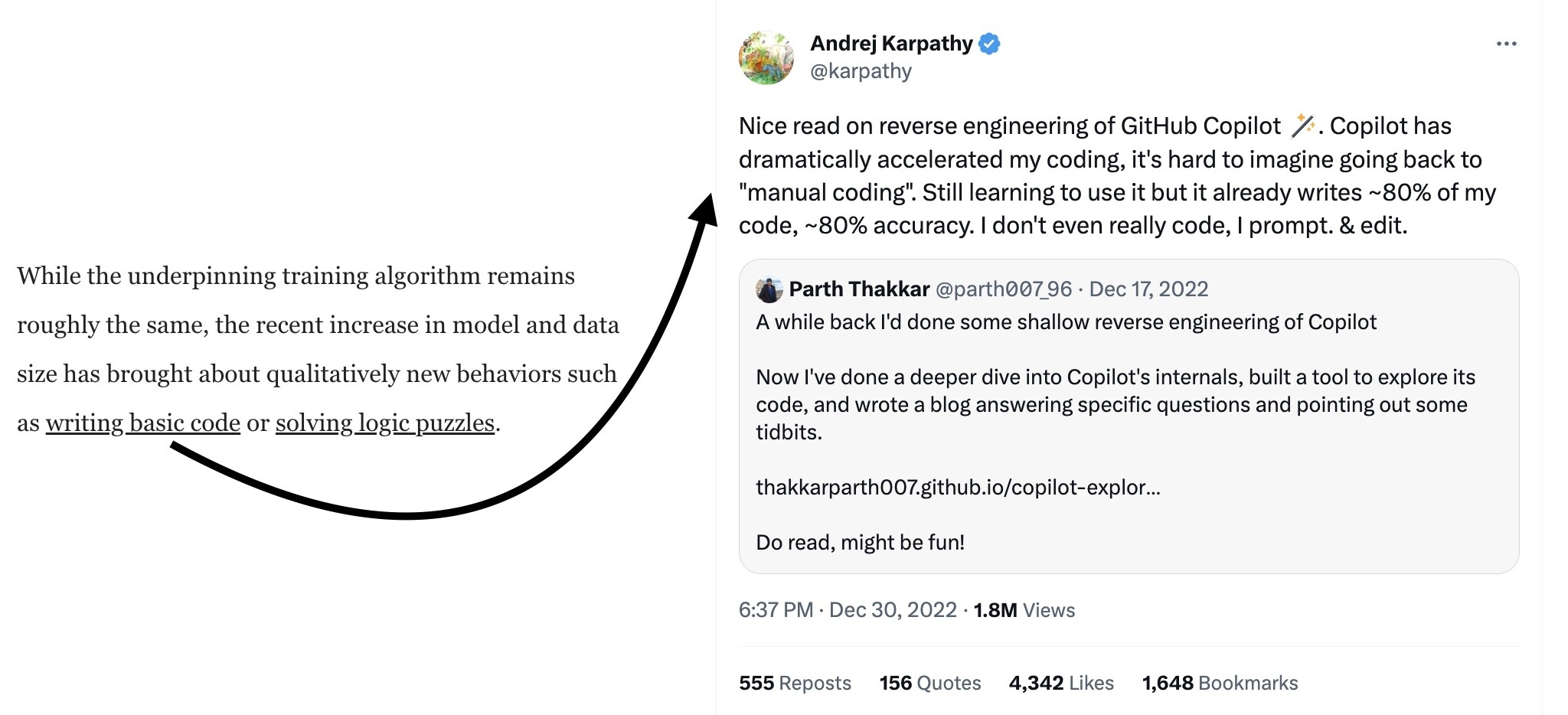
Footnote [1] is a tweet in praise of GitHub Copilot, which was trained on a large database of code. When Copilot writes code, this is not a “qualitatively new behaviour”; this is a model doing what it has been trained to do.
Footnote [2] is more puzzling. To support the claim that LLMs exhibit the “qualitatively new behaviour [of] solving logic puzzles”, the author cites a tweet by @dfeldman — which shows an LLM *failing* to do logic. The tweet asks: "Can GPT-3 solve simple logic puzzles?" and shows a series of GPT-3 phrase completion-based chats, beginning with:
Prompt: "Q: Alice is shorter than Bob. Bob is taller than Charlie. Is Alice shorter than Charlie? A:"
Completion: "Yes, Alice is shorter than Charlie."
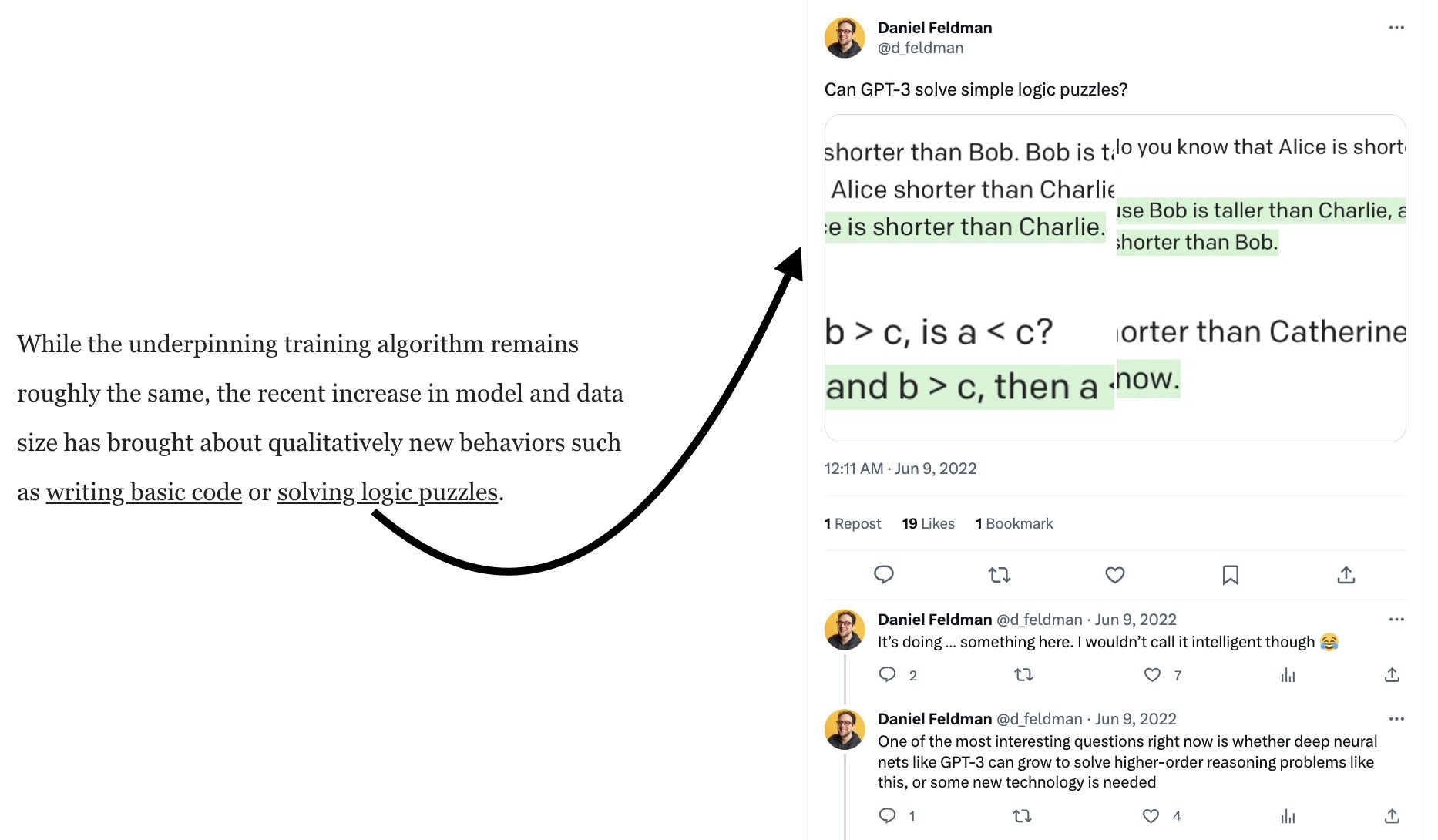


I’m left to wonder: when the author of the Othello blogpost cited this tweet, did they realise it contradicted their point? Or, when they saw the rhethorical question (“Can GPT-3 solve simple logic puzzles?”), did they just skim the screenshots, see that they looked vaguely like a chatbot solving a logic puzzle, and then assume that the answer to the question was “yes”?
Either way, these opening footnotes smack of something — whether sloppiness or credulousness, I don’t know if it matters!
@dfeldman’s tweet — from June 2022 — also left me curious about whether the current version of ChatGPT (3.5) would also fail to complete the syllogism. It did! So did Anthropic's Claude.
So, can text-completion systems solve logic puzzles? Well, solving a syllogism is a prerequisite to solving a logic puzzle. ChatGPT cannot solve a syllogism. Therefore... 

