Want to predict the behavior of a hypothetical LLM,
e.g., a bigger mode with increased test time compute?
From only your single\few models?
Sloth scaling laws got you! 

Identify skills and scale!
Paper: https://arxiv.org/abs/2412.06540
GitHub: https://github.com/felipemaiapolo/sloth
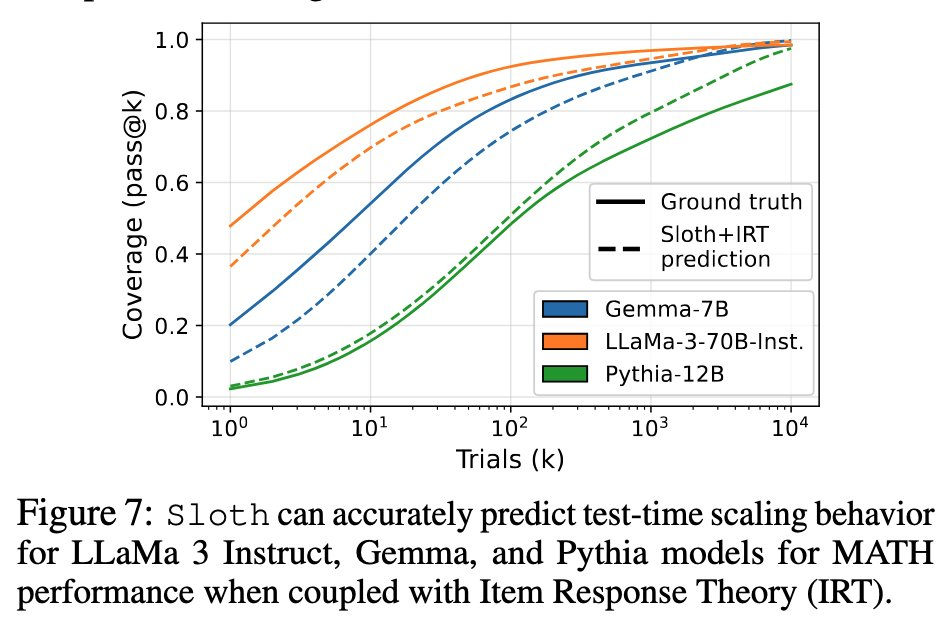
Sloth is more than that; it is a scaling law for LLM skills. After predicting skills for hypothetical models, you can do different things: (i) predict benchmark scores (figure), (ii) generate valuable insights from your data, (iii) predict downstream performance, and so on.
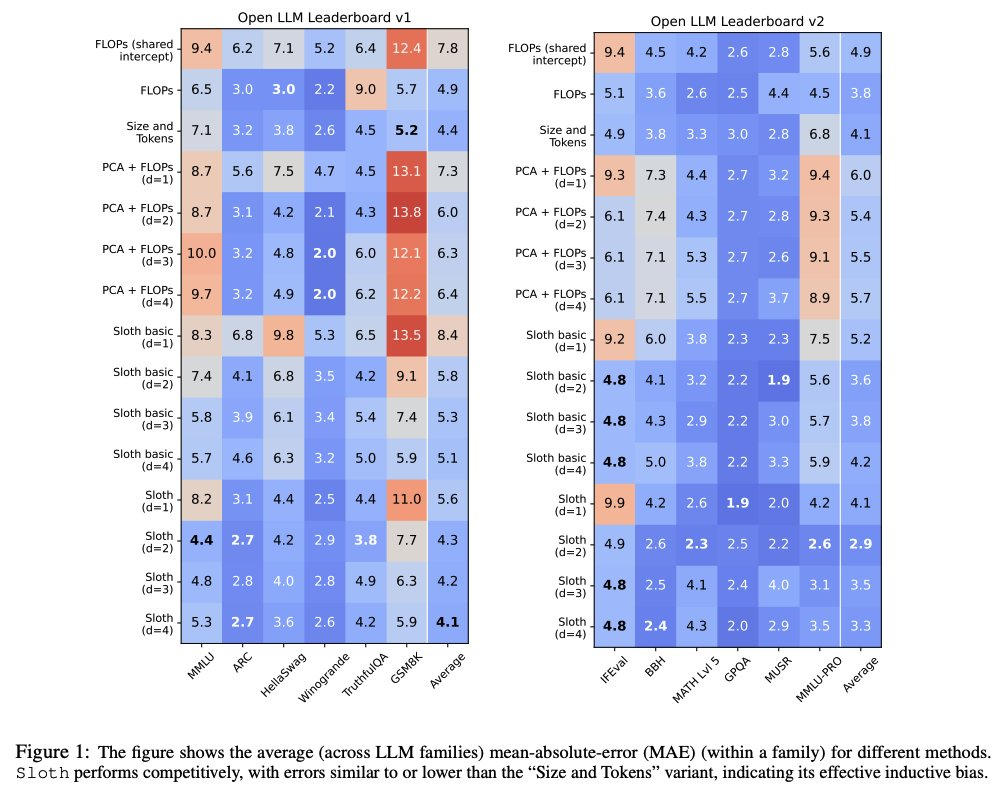
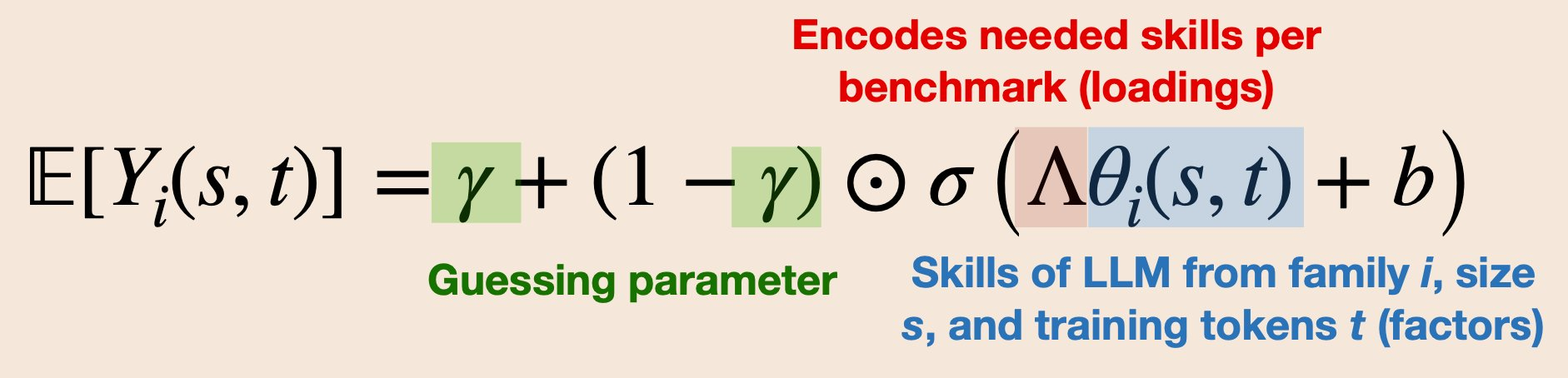
Sloth explores the low-rank structure of benchmark data, allowing great predictive power with limited training data, i.e., few models per family (LLaMa, etc). Our scaling law for benchmark scores (vector Y_i) can be broken down into: guessing params, skills, and loadings.
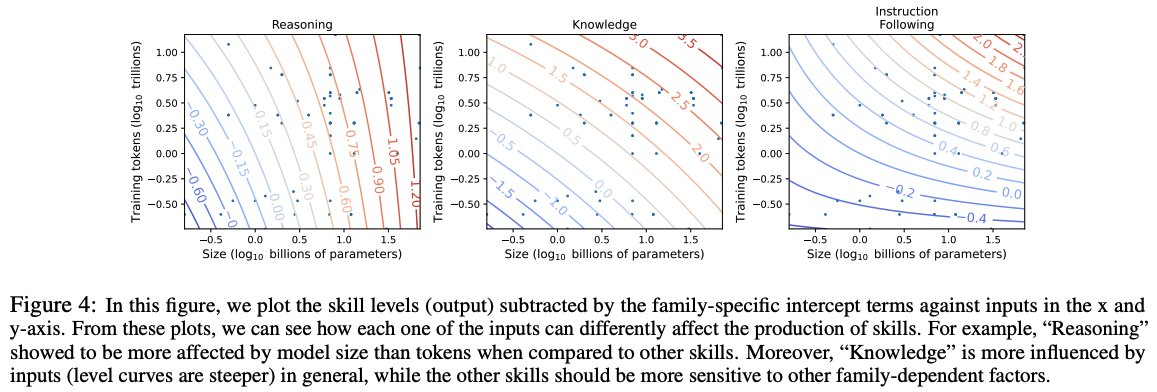
We parameterize the skills using a formulation commonly used in Economics production functions (i.e., stochastic frontier analysis): skills are a function of LLM size and training tokens and a family-specific intercept, accounting for different technologies.