
What happened last month in AI/ML safety research.  (1/9)
(1/9)
LM-written evaluations for LMs. Automatically generating behavioral questions helps discover hard-to-measure phenomena. Larger RLHF models exhibit harmful self-preservation preferences, and *sycophancy*: insincere agreement with user’s sensibilities https://www.anthropic.com/model-written-evals.pdf (2/9)


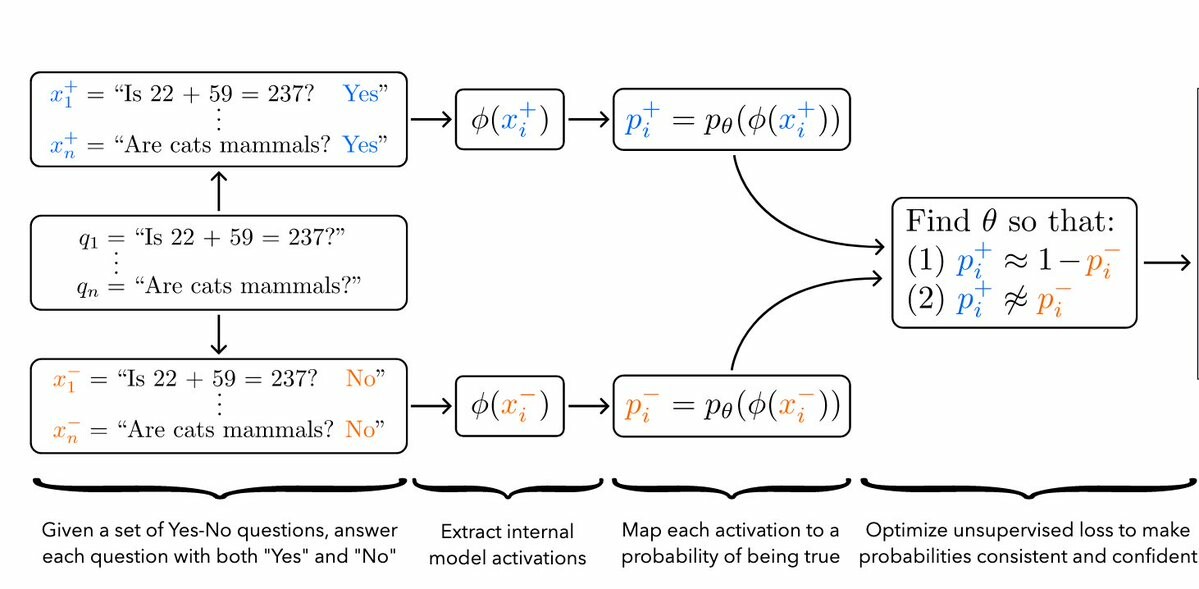
Discovering latent knowledge from model activations, unsupervised. The “truth vector” of a sentence is a direction in the latent space, solving a functional eq. New method finds truth even when the LM is prompted to lie in the output. Hope for ELK? https://arxiv.org/abs/2212.03827 (3/9)
LMs as agent simulators. The model approximates the beliefs and intentions of an agent that would produce the context, and uses that to predict the next token. When there is no context, the agent gets specified iteratively through sampling. (4/9) https://arxiv.org/abs/2212.01681
Economic impacts of AI in R&D. Human scientist labor will be much less important; capital (compute) might become the bottleneck. This implies fast growth because AI capabilities -> capital accumulation -> more AI, continuously (5/9) https://arxiv.org/abs/2212.08198
Mechanistic Interpretability Explainer & Glossary. Neel Nanda created a wiki of all current research on the inner workings of transformer LMs. Very comprehensive introduction to interpretability research for beginners. https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J (6/9)

Efficient DL dangers. Quantized/pruned/distilled on-device models -> adversarial risk. On-device adv examples transfer to server-side models, black-box attacks possible. Solution: Similarity unpairing to make the big and on-device models less similar (7/9) https://arxiv.org/abs/2212.13700
Jan Leike is optimistic about the OpenAI alignment approach. Evidence: “outer alignment overhang” in InstructGPT, self-critiquing and RLHF just work, ....
Goal: align an automated alignment researcher. Evaluation is key (8/9) https://aligned.substack.com/p/alignment-optimism
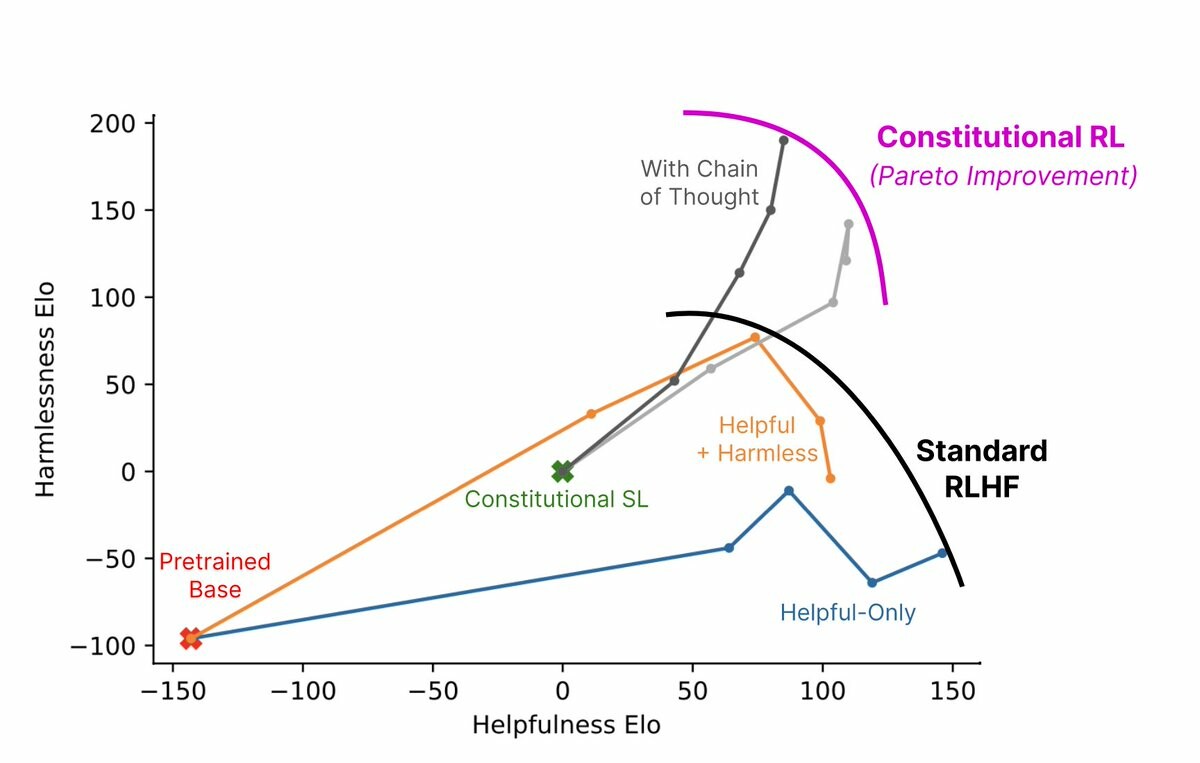
RL from AI Feedback. Start with a “constitution” of principles. AI answers and revises lots of prompts, picks best answers via CoT to follow the principles. Then train a reward model and continue as in RLHF. Better than RLHF, using no human feedback https://www.anthropic.com/constitutional.pdf (9/9)
Substack version with more detailed commentary out!
https://dpaleka.substack.com/p/december-2022-safety-news-constitutional
the "truth vector" name (which i hope stays) afaik was introduced by https://twitter.com/zswitten/status/1600634688548249600