


 Released my "Image Mixer" model!
Released my "Image Mixer" model!
Mix up concepts in multiple images and words to generate novel pictures!
Try it on @huggingface spaces here: https://huggingface.co/spaces/lambdalabs/image-mixer-demo
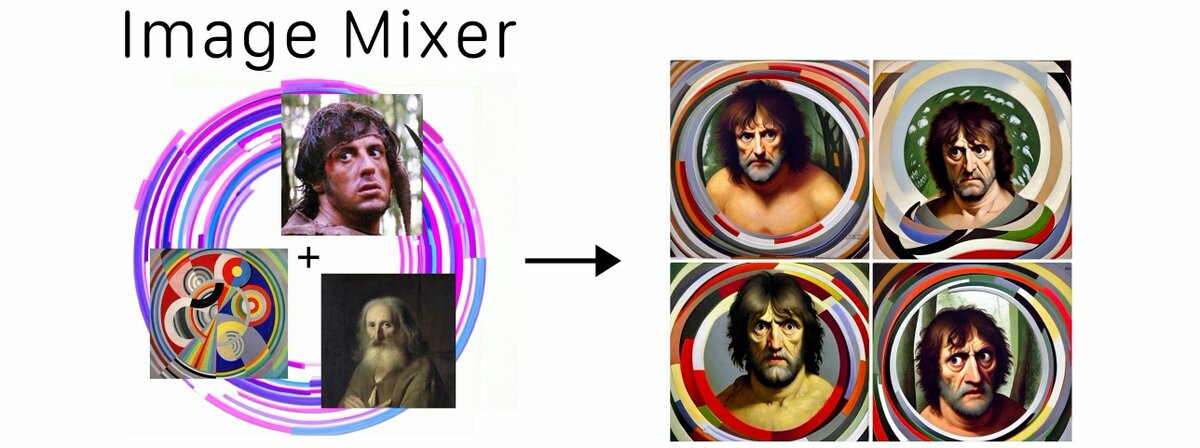
The model is trained to take multiple CLIP embeddings and tries to use all of these to generate an image. This encourages it to mix the most prominent features from each of the inputs.
I shared a thread recently with a few examples:
---
RT @Buntworthy
Making a mix and match demo
https://twitter.com/Buntworthy/status/1615302310854381571
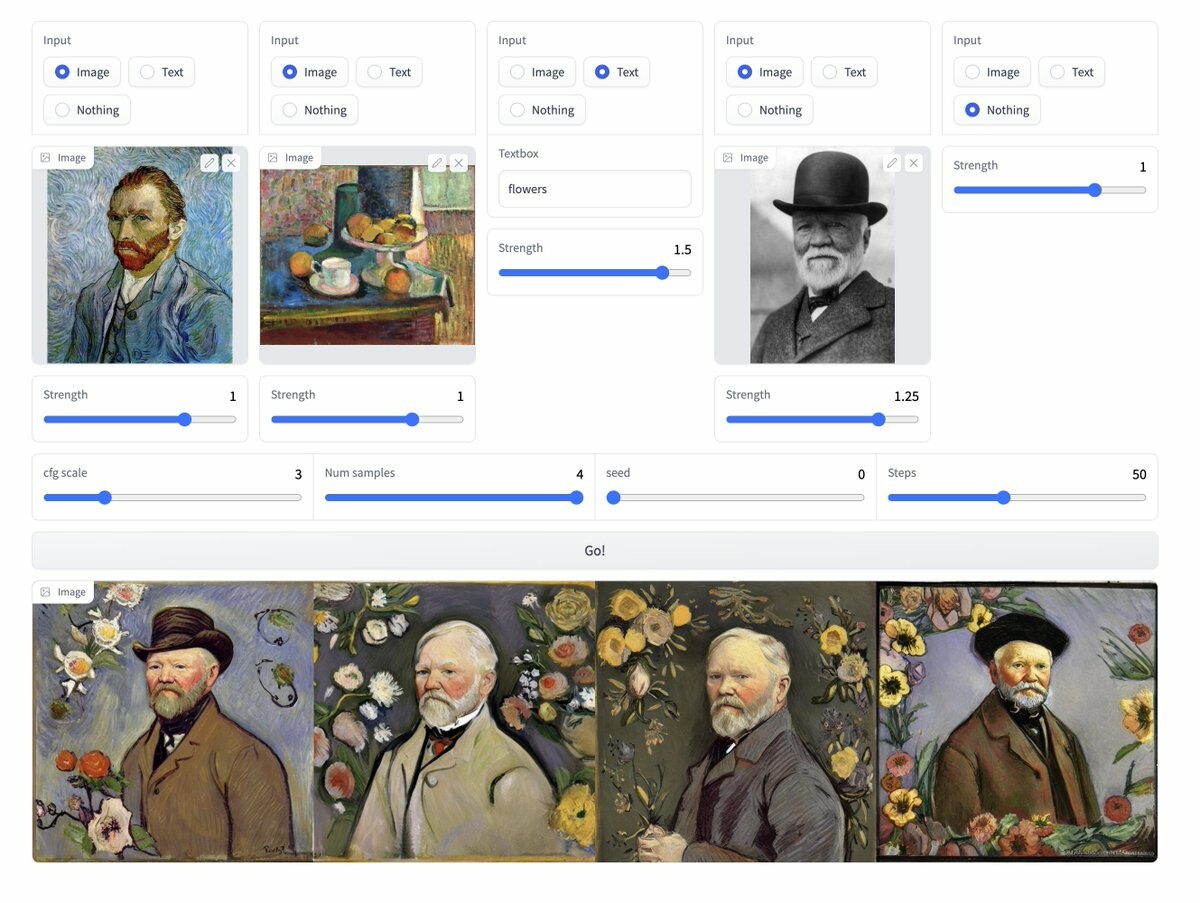
Each input has a strength parameter which requires tweaking in order to find the right balance for all the inputs to be combined properly, here's an example of the typical workflow I go through.
You can get the trained model .ckpt as well as instructions for running it locally on huggingface hub: https://huggingface.co/lambdalabs/image-mixer
It's a fine-tuned version of my previous Image Variations model and was trained using 8xA100s from @LambdaAPI