

New preprint 
DSI++: Updating Transformer Memory with New Documents
Q: "Can you add new documents to DSI??" was the big question many people had when DSI first came out.
A: Turns out you actually can!
https://arxiv.org/abs/2212.09744
(1/n)
Q: What is DSI?
A: https://twitter.com/YiTayML/status/1494710879429877761?s=20&t=nPEqUUI4wcC9loqVPc3b2w
DSI paper  https://openreview.net/forum?id=Vu-B0clPfq
https://openreview.net/forum?id=Vu-B0clPfq
(2/n)
Q: Why DSI++?
A: Deploying the DSI model in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model
(3/n)
Q: What is DSI++?
A: DSI++ (DSI + new documents) a step towards incrementally indexing new documents in the DSI model by being computationally efficient and maintaining the ability to answer user queries related to both previously and newly indexed documents
(4/n)
Q: What are the challenges for enabling DSI++?
A: (a) Catastrophic forgetting during continual indexing a common phenomenon in neural networks wherein learning of the new documents interferes with the previously memorized documents
(5/n)
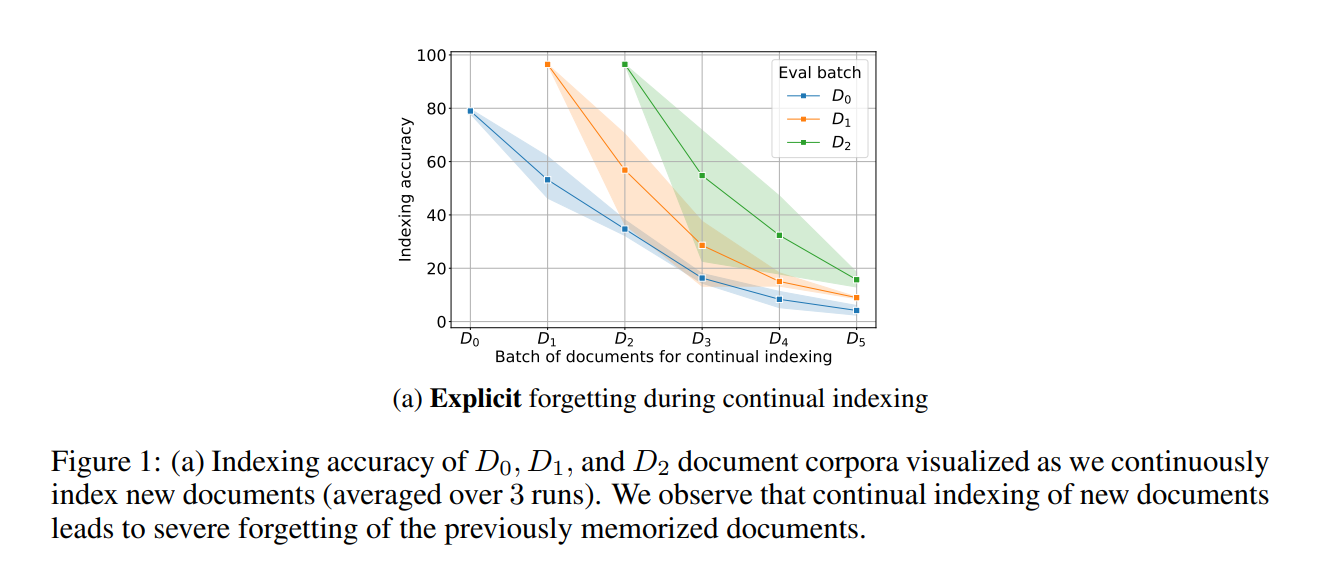
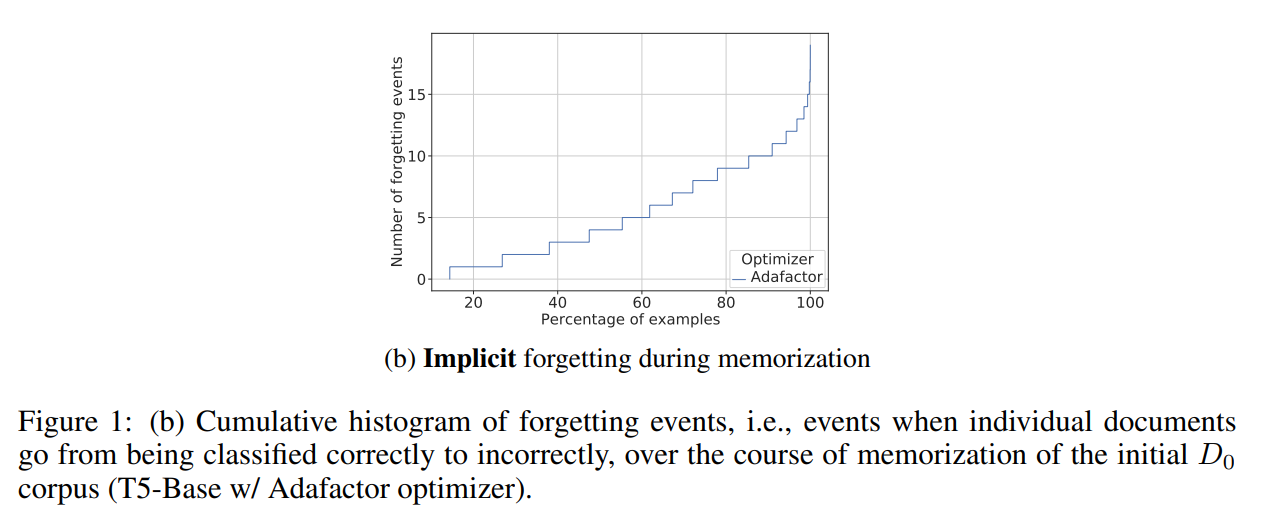
…(b) Implicit forgetting during memorization we observe a significant number of documents (~88%) experience forgetting events (when prediction for an individual document goes from correct docid to incorrect one) after they have been memorized
(6/n)
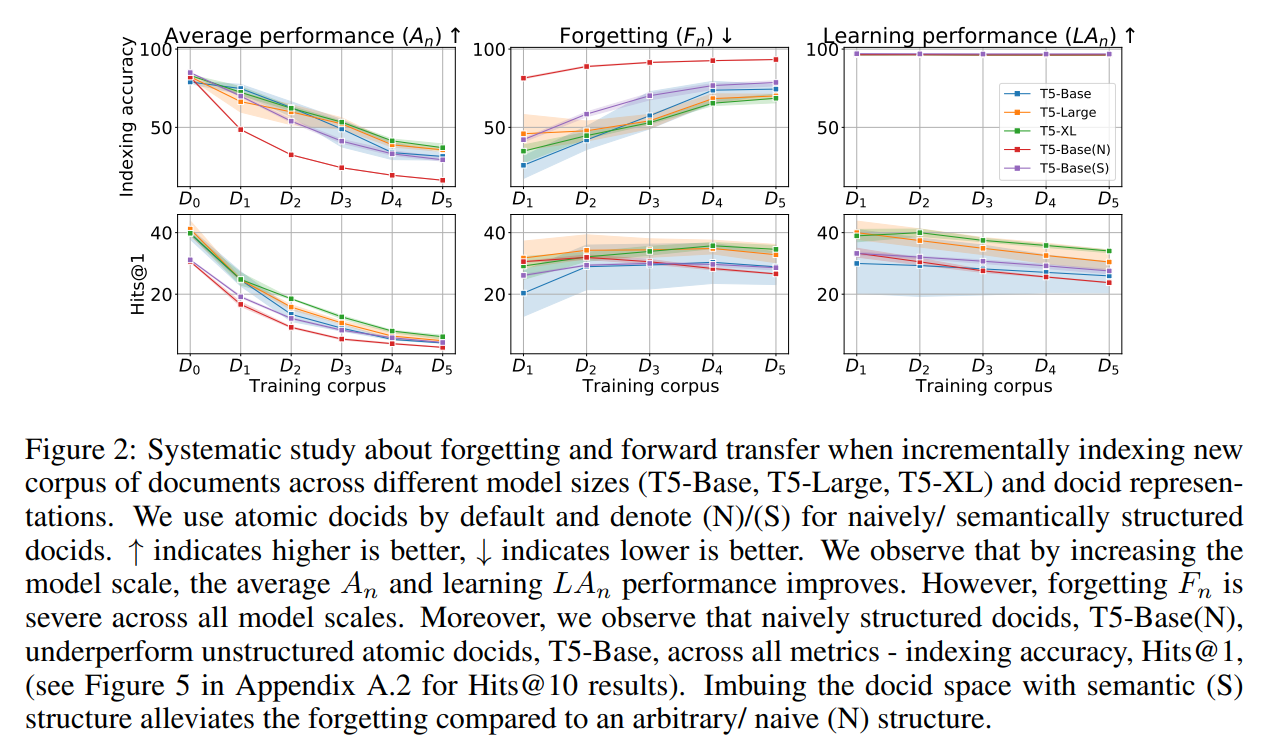
Q: How severe is the forgetting of the originally indexed documents? How does the updated DSI model perform on newly indexed documents? How do different docid representation strategies affect forgetting? How does the DSI model scale affect forgetting?
A: Systematic study 
(7/n)
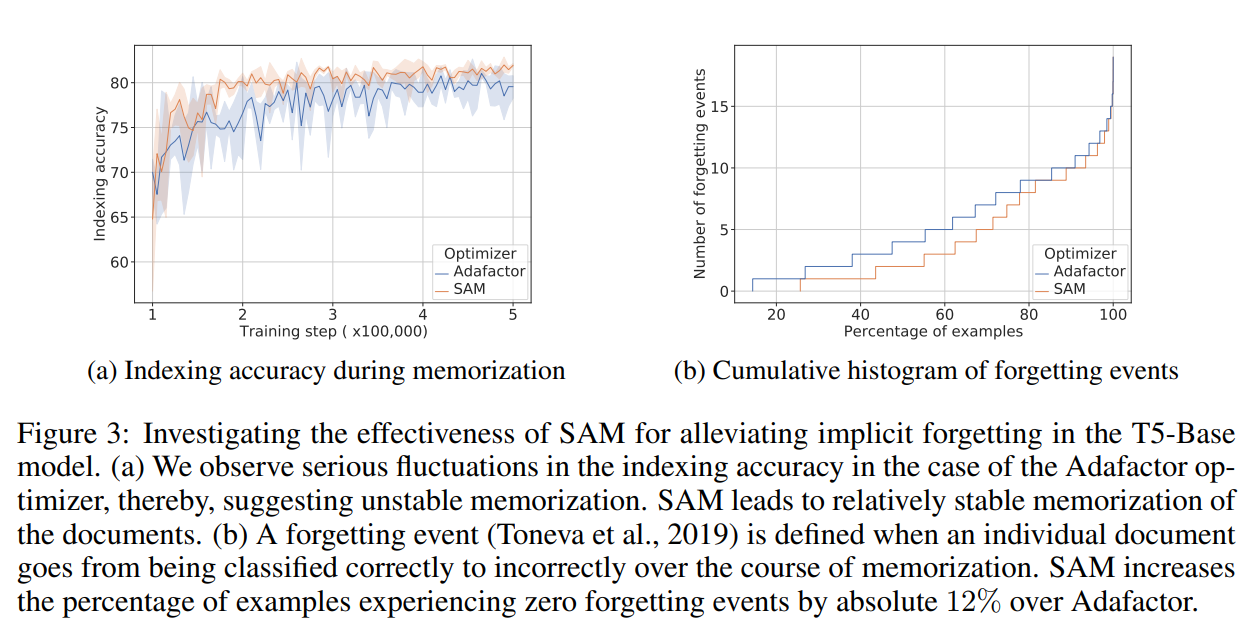
Q: How to reduce forgetting during memorization?
A: Flatter minima are shown to reduce forgetting...we explicitly optimize for flatter minima using Sharpness-Aware Minimization (SAM) procedure...see our results
SAM paper https://openreview.net/forum?id=6Tm1mposlrM
(8/n)
Q: How to alleviate forgetting during continual indexing?
A: Generative memory a parametric model to generate queries for documents…use it for sparse experience replay (ER) for already indexed documents...enables continual semi-supervised learning for new documents...
(9/n)
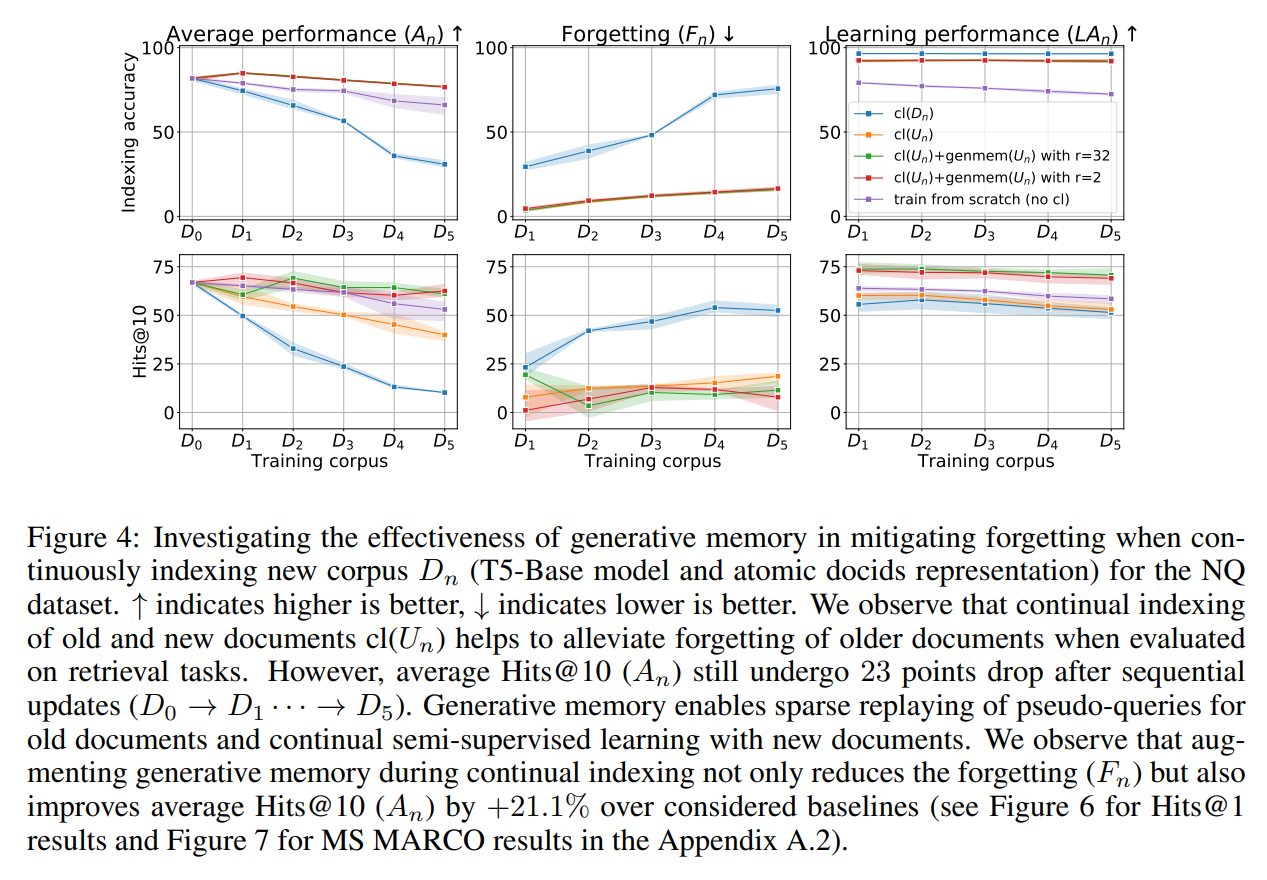
Q: Does our proposed approach for DSI++ generalize to different datasets?
A: We show convincing results across two DSI++ benchmarks, constructed from publicly available datasets – Natural Questions (NQ)  and MS MARCO
and MS MARCO
(10/n)
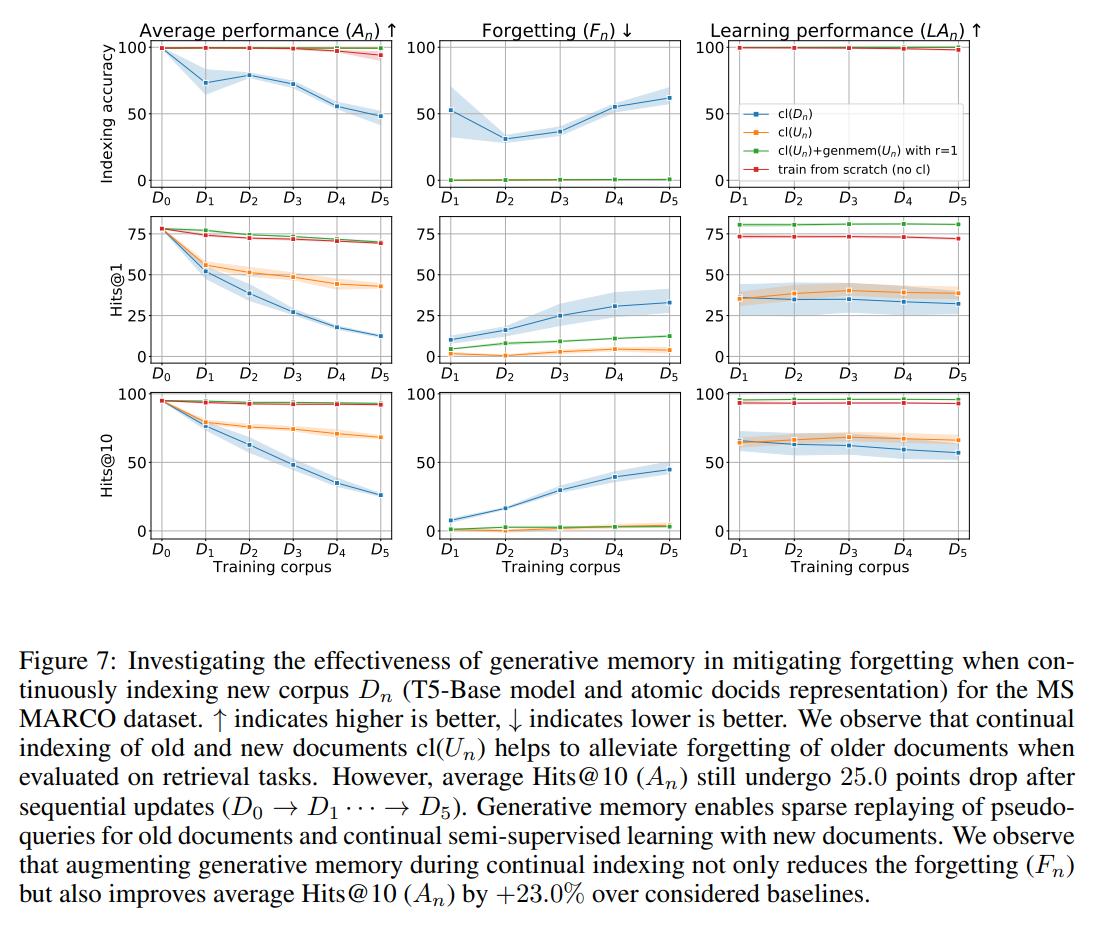
Q: Want to know more?
A: Look at our paper for the effectiveness of the generative memory with the scale of a corpus (8.9M MS MARCO passages), sparsity of ER on forgetting, analysis around incremental index construction time
DSI++ paper arxiv.org/abs/2212.09744
(11/n)
