

Do LLMs learn foundational concepts required to build world models? (less than expected)
We address this question with 
 EWoK (Elements of World Knowledge)
EWoK (Elements of World Knowledge)
a flexible cognition-inspired framework to test knowledge across physical and social domains
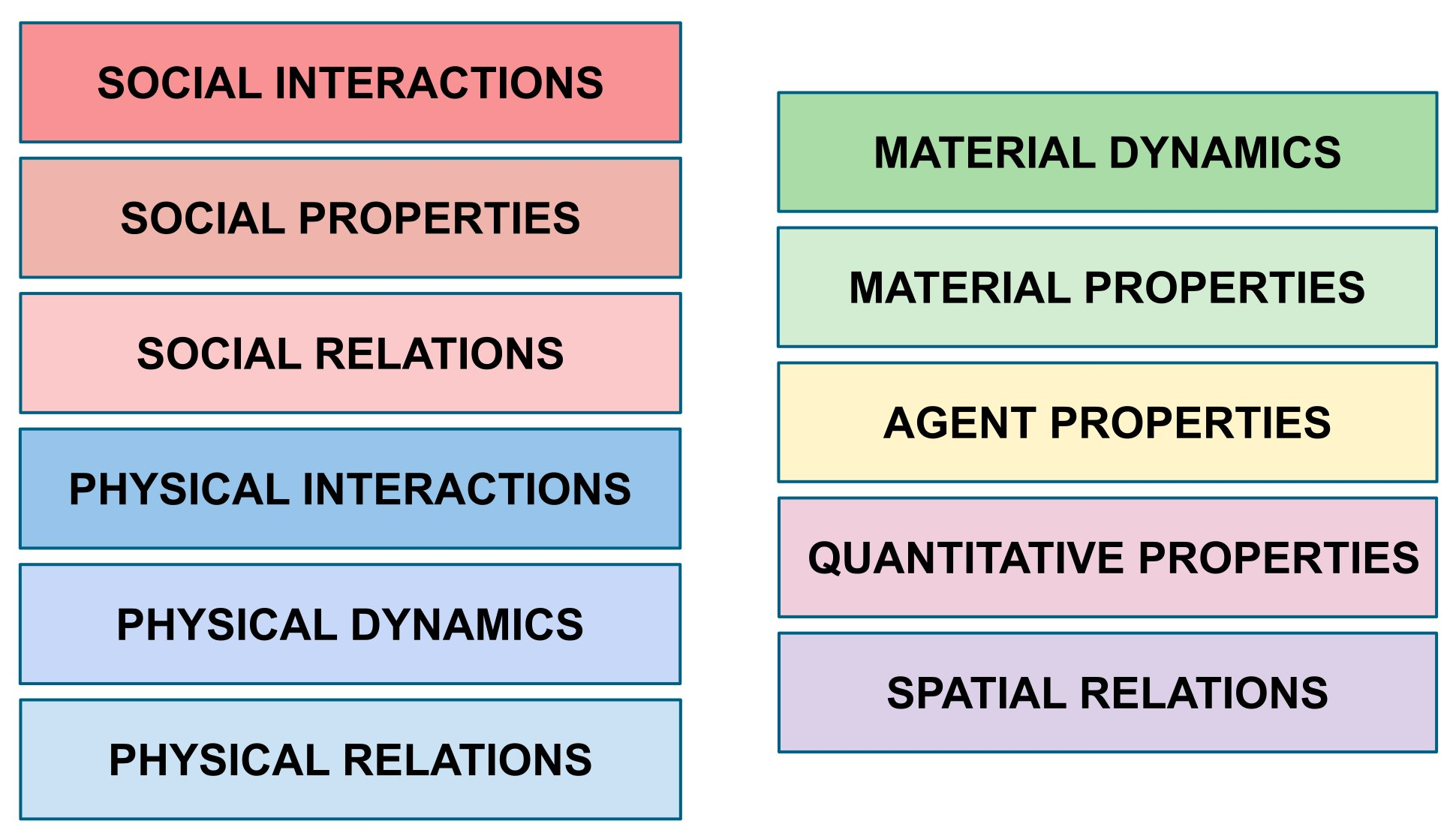
We leveraged the cognitive science literature to select concepts from 11 domains of knowledge, from social interactions (HELP, HINDER, CHASE, EVADE) to spatial relations (LEFT, RIGHT, CLOSE, FAR)
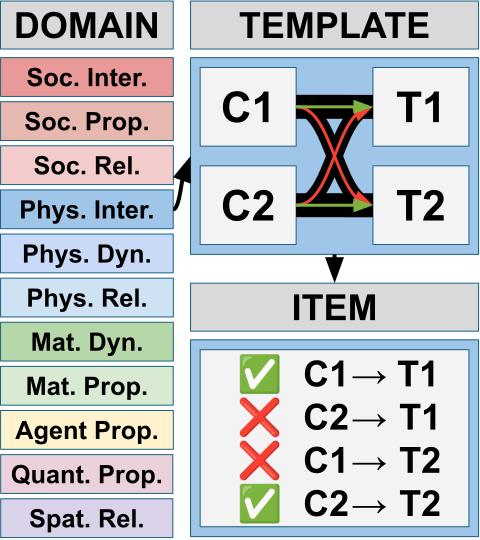
We then designed *templates* probing the knowledge of these concepts. Each template has 2 contexts (C) and 2 targets (T), such that T1 is plausible given C1 but not C2 and vice versa
This way, we are eliminating simple reliance on the option that’s more common in training data
A template can be completed with different fillers, generating many unique *items*
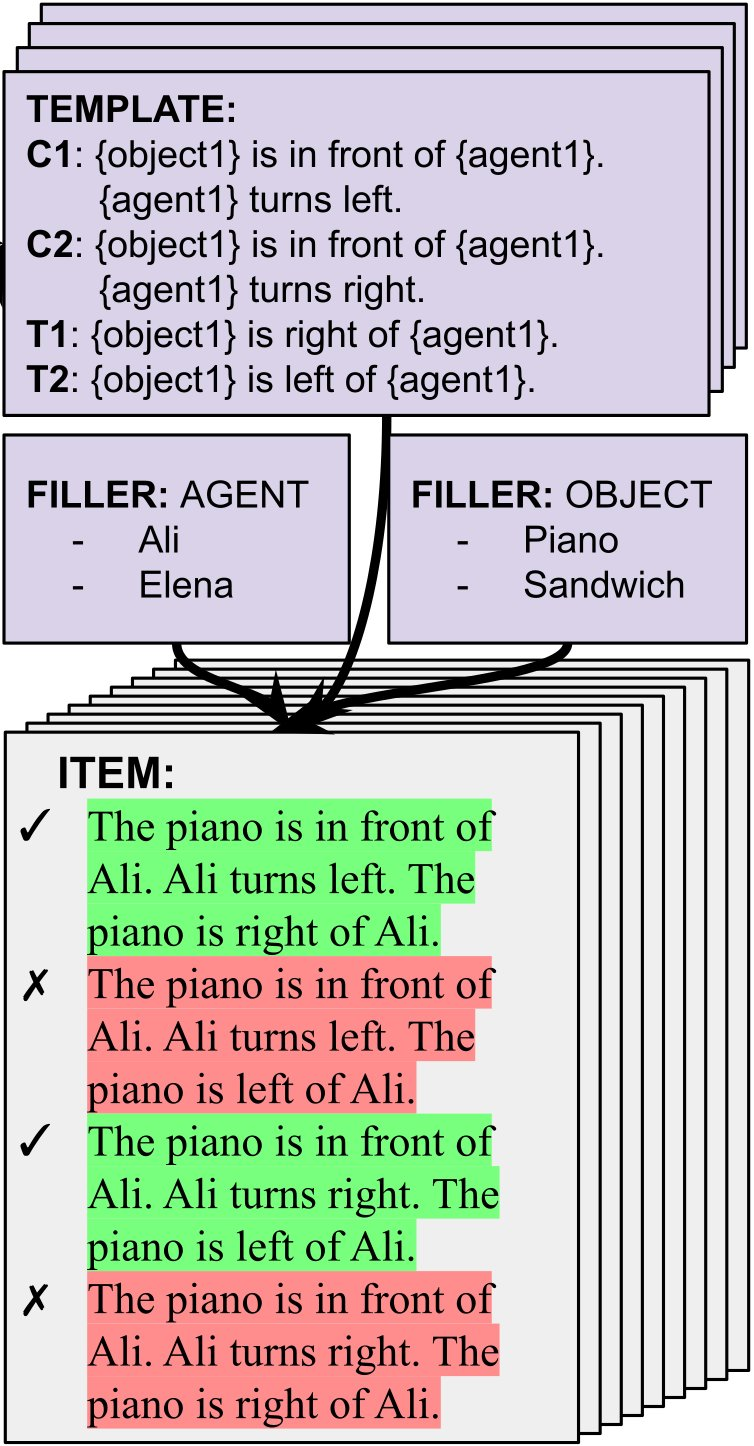
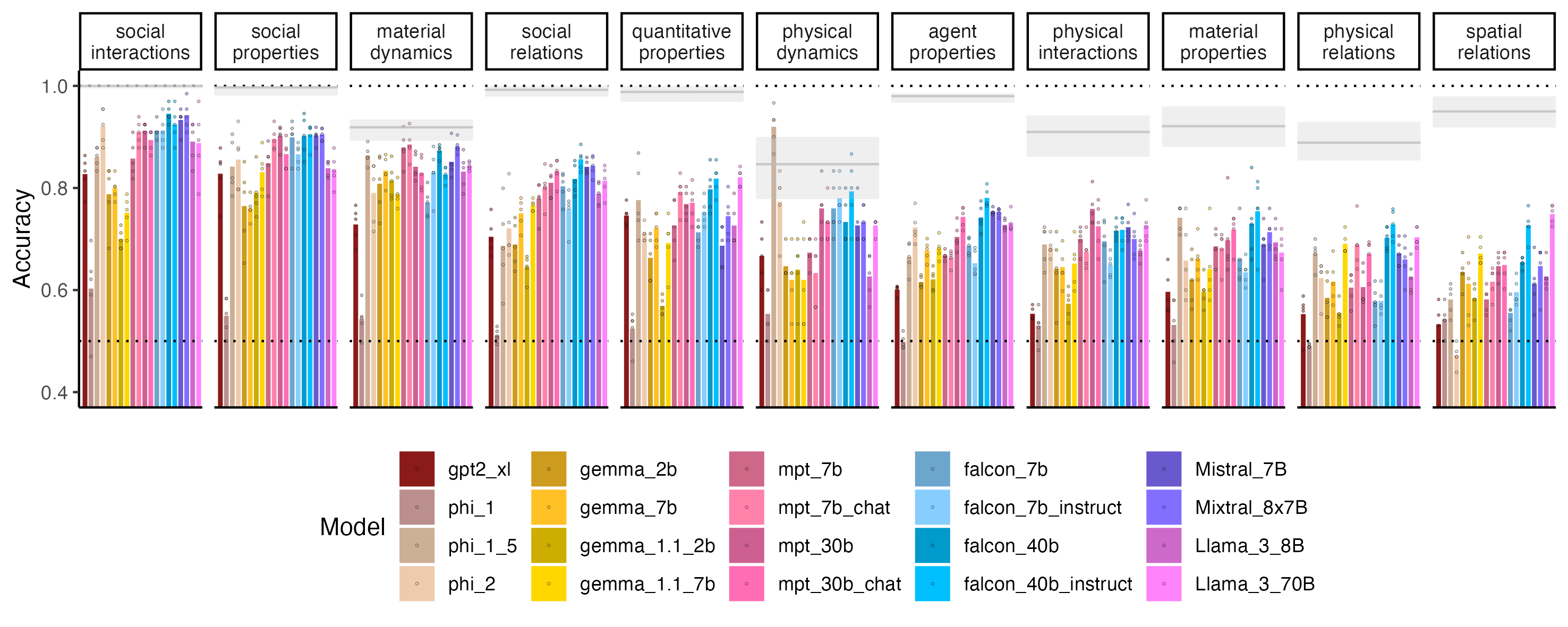
Using the EWoK framework, we generated the EWoK-core-1.0 dataset comprising 4,374 items. We then tested 20 open-weights LLMs (1.3B-70B params) and compared them with humans (12,480 measurements)
Our easiest domain was social interactions (HELP, HINDER, CHASE, EVADE), followed by social properties (FRIENDLY, HOSTILE, HUMBLE, BOASTFUL)
Bars = LLMs; dots = dataset versions (different fillers). Chance 0.5
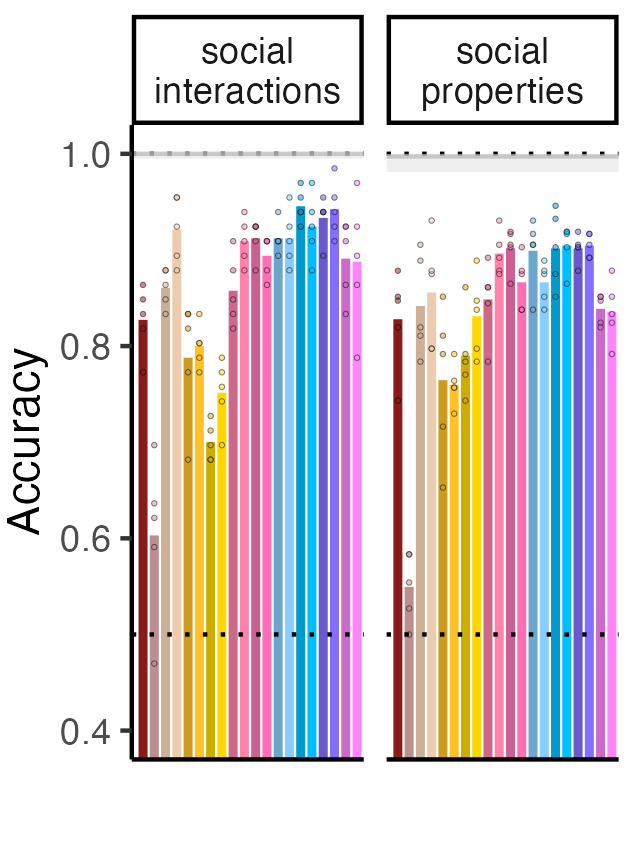
Our hardest domains are physical relations (CONTAIN, SUPPORT, BLOCK) and spatial relations (LEFT, RIGHT, CLOSE, FAR). Human performance (shaded in gray, range = performance on diff versions) is also below perfect but still much better than LLMs
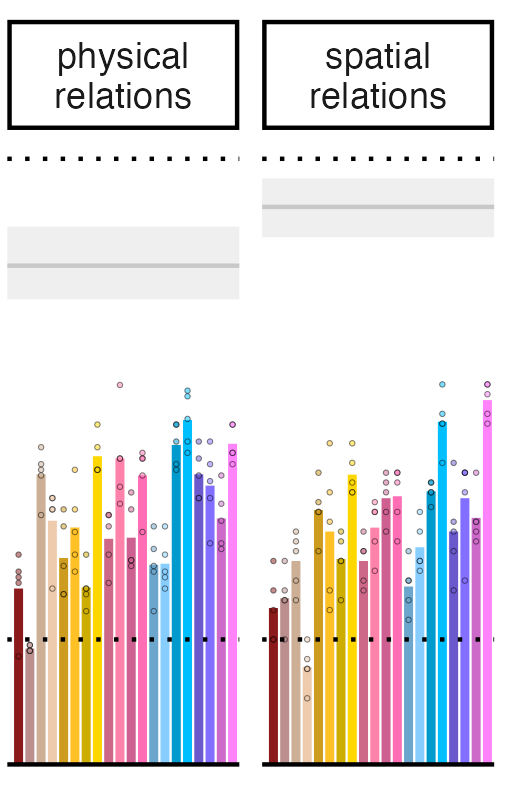
Overall, performance improves with latest & larger models but not by much! Domains that are hard are mostly hard for all models (but not necessarily for humans)
See paper for additional controls and result nuggets
Lots of new places to go from here! More domains, targeted experiments on the effects of fillers/context-target links, locating domain knowledge inside LLMs…
We make the EWoK data generation framework available for all, feel free to build on it!
We spent a lot of time thinking about protecting EWoK from immediately contaminating the training data. Ultimately, the responsibility lies with you!  Do not openly post the items/templates online AND report whenever you train/finetune a model on EWoK-generated items
Do not openly post the items/templates online AND report whenever you train/finetune a model on EWoK-generated items
The items used in the paper, EWoK-core-1.0, are available on HuggingFace  :
:
https://huggingface.co/datasets/ewok-core/ewok-core-1.0
The code to replicate our results is here:
https://github.com/ewok-core/ewok-paper
Preprint here: https://arxiv.org/abs/2405.09605
Feedback welcome!

@LChoshen I was just talking about this problem with a friend the other day. Really interesting data, thank you for sharing!