

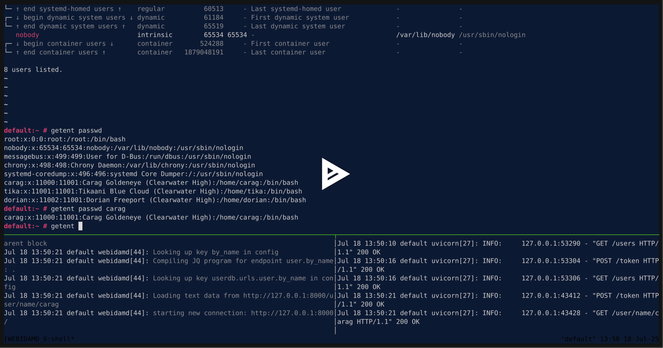
Setting up a sector-wide #PeerTube pilot instance on behalf of Dutch higher ed & research using #SSO via #SAML, so no local usernames/passwords…
Anyone with experience uploading videos using the #REST #API for system integration purposes? No classic #OAuth flow here… or is it possible?!

 #Framasoft #Fediverse #OpenSource #Education #Science #askfedi
#Framasoft #Fediverse #OpenSource #Education #Science #askfedi

video.edu.nlvideo.edu.nlVideo.edu.nl, is een PeerTube pilot videoplatform van SURF.






 Blain Smith
Blain Smith 












 Serbia
Serbia Full-time
Full-time Tide
Tide




















