
We have data from @chartbeat that backs up Google, saying traffic from Google to publishers is stable since AI Overviews https://www.seroundtable.com/chartbeat-traffic-google-data-39943.html hat tip @glenngabe @pressgazette.co.uk

#publishers
3 posts3 participants0 posts today




Hey, I just read something interesting.
Even though the Icelanders published it, this type of email theft could happen to anyone. Be sure to check the email provider of a name you know ... it could use YOUR name and another provider to steal YOUR email traffic ...

I trust #InternetArchive with government documents more than I do the government! (Or #AI for that matter...)
Internet Archive is now an official #USGovernment document #library
by Steve Dent
Fri, July 25, 2025
"The US Senate has granted the Internet Archive federal depository status, making it officially part of an 1,100-library network that gives the public access to government documents, #KQED reported. The designation was made official in a letter from California Senator Alex Padilla to the Government Publishing Office that oversees the network. 'The Archive's digital-first approach makes it the perfect fit for a modern #FederalDepositoryLibrary, expanding access to federal government publications amid an increasingly digital landscape,' he wrote.
"Established by Congress in 1813, the Federal Depository Library Program is designed to help the public access government records. Each congressional member can designate up to two libraries, which include government information like budgets, a code of federal regulations, presidential documents, economic reports and census data.
"With its new status, the Internet Archive will be gain improved access to government materials, founder Brewster Kahle said in a statement. 'By being part of the program itself, it just gets us closer to the source of where the materials are coming from, so that it’s more reliably delivered to the Internet Archive, to then be made available to the patrons of the Internet Archive or partner libraries.' The Archive could also help other #libraries move toward #DigitalPreservation, given its experience in that area.
"It's some good news for the site which has faced legal battles of late. It was sued by major #publishers over loans of #DigitalBooks during the #Coronavirus epidemic and was forced by a federal court in 2023 to remove more than half a million titles. And more recently, major music labels filed lawsuits over its #Great78Project that strove to preserve #78RPM records. If it loses that case it could owe more than $700 million damages and possibly be forced to shut down.
"The new designation likely won't aid its legal problems, but it does affirm the site's importance to the public. 'In October, the Internet Archive will hit a milestone of 1 trillion pages,' Kahle wrote. 'And that 1 trillion is not just a testament to what libraries are able to do, but actually the sharing that people and governments have to try and create an #EducatedPopulace.' "
https://tech.yahoo.com/general/articles/internet-archive-now-official-us-123036550.html
Yahoo Tech · Internet Archive is now an official US government document library

Google denies AI search is harming publisher traffic 
It claims overall click volume is “stable” and click quality has increased—but offers no data 
Still, third-party reports show rising zero-click rates & declining news site referrals since AI Overviews launched 
@sarahp.bsky.social
@Techcrunch@flipboard.com
@techcrunch@threads.net
https://techcrunch.com/2025/08/06/google-denies-ai-search-features-are-killing-website-traffic/

TechCrunch · Google denies AI search features are killing website traffic | TechCrunchThough Google hasn't shared any specific data to back up its conclusions, even if we assume Google's claims to be true, this doesn't necessarily mean that AI isn't having an impact.

eContent Pro International Press is confused.
https://www.researchinformation.info/news/u-s-book-publisher-launches-under-platinum-open-access-model/
It says it's “the first U.S.-based book publisher to operate exclusively under a #platinum #OpenAccess publishing model."
But it also says that "the open access processing charges that offset the publication costs are funded by individuals, sponsoring institutions, grants, and so on" and that it's "committed to offering some of the lowest Book Processing Charges (#BPCs) in the industry."

Generative AI assistants are cutting into traditional online search traffic, depriving news sites of visitors and impacting the ad revenue they desperately need, in a blow to an industry already fighting for survival. https://www.japantimes.co.jp/business/2025/08/04/tech/ai-search-media-ecosystem/?utm_medium=Social&utm_source=mastodon #business #tech #chatgpt #ai #fakenews #misinformation #media #journalism #pressfreedom #censorship #newspapers #magazines #internet #publishers

The Japan Times · AI search pushing an already weakened media ecosystem to the brink
Press Gazette: Cyberattacks target email accounts of senior journalists. “Publishers of all sizes have been warned after cyberattacks took over the email accounts of senior staff at British publishers. The warning comes as The Washington Post investigated a similar attack on email accounts of journalists, with an intrusion discovered in June, and all staff passwords reset as a precaution.”
Very promising. Watching with interest.
https://thebrick.house/briet/
"The right of #libraries to own their own collections is the bedrock of cultural #preservation. #Books that can’t be owned [but merely licensed] are books that can be tampered with, or even taken away. To demonstrate the right way for #publishers to work with, and not against, libraries, the independent publishers of Brick House sold our first ebook to a library in 2021; since then we’ve been at work developing #BRIET, so that fellow publishers could do the same…It’s free to use, for both publishers and libraries."
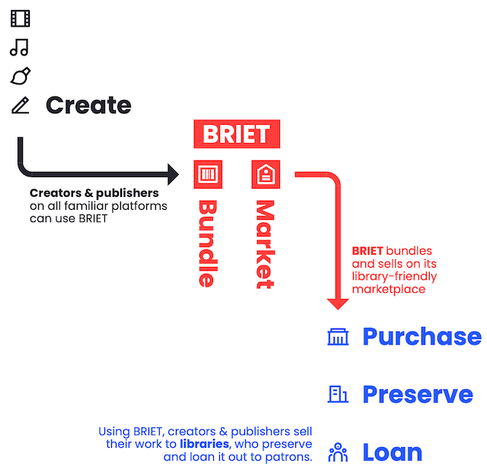
The Brick House CooperativeBRIET - The Brick House CooperativeSELL your ebooks, to libraries, for keeps. PROTECT libraries. BRIET is a groundbreaking new project of the Brick House Cooperative. Using BRIET, independent publishers can sell (not license) permanent copies of quality ebooks directly to libraries and schools to loan to patrons, just as they would with paper books. The right of libraries to own their […]

ICYMI: #Publishers, #Booksellers, and #Authors File Amicus Brief Challenging Unconstitutional Iowa Law (via @americanpublish.bsky.social) https://publishers.org/news/publishers-booksellers-and-authors-file-amicus-brief-challenging-unconstitutional-iowa-law/ #books #bookbans
Mashable: Google is reportedly pursuing AI licensing deals with news publishers. “According to Bloomberg, Google is reportedly preparing to launch a ‘pilot project initially with about 20 national news outlets,’ where the participants would license their content for Google’s AI tools. There isn’t much detail beyond the initial report, but it sounds similar to the strategy that OpenAI has […]

ResearchBuzz: Firehose | Individual posts from ResearchBuzz · Mashable: Google is reportedly pursuing AI licensing deals with news publishers | ResearchBuzz: Firehose
More from  ResearchBuzz: Firehose
ResearchBuzz: Firehose

Johns Hopkins Press Plans to License Books to Train AI https://www.insidehighered.com/news/faculty-issues/books-publishing/2025/07/25/johns-hopkins-press-plans-license-books-train-ai #AI #publishers #training

Johns Hopkins Press Plans to License Books to Train AI https://www.insidehighered.com/news/faculty-issues/books-publishing/2025/07/25/johns-hopkins-press-plans-license-books-train-ai #AI #publishers #training
Business Insider: "Here's the List of Websites Gig Workers Used to Fine-Tune Anthropic's #AI Models. Its Contractor Left It Wide Open" https://www.infodocket.com/2025/07/23/business-insider-heres-the-list-of-websites-gig-workers-used-to-fine-tune-anthropics-ai-models-its-contractor-left-it-wide-open/ #libraries #publishers #publishing
The #AuthorsAlliance (@AuthorsAlliance) just updated its excellent FAQ on the new #NIH #OpenAccess policy.
Here's the original FAQ from June 6, 2025.
https://www.authorsalliance.org/2025/06/06/the-nih-public-access-policy-qa-for-authors/
Here's the update from July 18, 2025, answering several additional questions.
https://www.authorsalliance.org/2025/07/18/an-update-nih-and-publisher-guidance-what-authors-need-to-know-about-nihs-public-access-policy/

Ganz anders sieht es offenbar mit leicht übersetzbarer #Literatur aus. Bei einem auf Genre und leichte Kost spezialisierten Verlag wie Bastei Lübbe scheinen die Dämme schon gebrochen zu sein. Die #ubersetzerin Janine Malz machte vor einiger Zeit öffentlich, dass der #Verlag sie damit beauftragen wollte, eine KI-#Übersetzung ins Reine zu übertragen - und das für ein Viertel des sonst üblichen Honorars. ..
https://www.perlentaucher.de/efeu/2025-07-22.html
Perlentaucher - Online KulturmagazinEfeu - Die Kulturrundschau vom 22.07.2025 | Übersetzung und KI. Neues Streaming-Gesetz in Russland. Tod des Deutschraps.Die besten Kritiken vom Tage. Wochentags um 9 Uhr, sonnabends um 10 Uhr.
"Global cost of silencing science: editors and publishers have a duty to resist."
https://nzmj.org.nz/journal/vol-138-no-1618/global-cost-of-silencing-science-editors-and-publishers-have-a-duty-to-resist
This is an editorial in the New Zealand Medical Journal, reprinted in The Lancet. Both versions are paywalled. If it helps, here's the Lancet copy.
https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(25)01429-1/abstract
"Authoritarian regimes elsewhere see the USA as setting a precedent, finding in Trump’s agenda a justification to suppress dissent, censor scientific dialogue, and delegitimise independent inquiry…Scientific research, especially in medicine and public health, is inherently intertwined with social justice. Silencing DEI initiatives, censoring climate science, and delegitimising minority researchers is not neutrality—it is complicity in perpetuating harm. Resistance is not without precedent…Whistleblowers, journal editors, and advocacy organisations have long served as guardians of scientific freedom. Today, that tradition must continue with renewed vigour. Editorial boards must uphold their independence. Universities and scientific bodies must defend faculty facing retribution. Policy makers must embed protections for scientific freedom into the legislative framework."
The New Zealand Medical JournalGlobal cost of silencing science: editors and publishers have a duty to resistThe New Zealand Medical Journal (NZMJ) is the principal scientific journal for the medical profession in New Zealand. The Journal has become a fundamental resource for providing research and written pieces from the health and medical industry.
Tubefilter: Amid money troubles, Scholastic is seeking its next chapter on YouTube. “As part of the restructuring, and amid all these money troubles, Scholastic is taking a gamble: spending $182 million to acquire 9 Story Media Group, a Toronto-based animation studio it hopes can help turn its most popular books into view-raking YouTube content.”

ResearchBuzz: Firehose | Individual posts from ResearchBuzz · Tubefilter: Amid money troubles, Scholastic is seeking its next chapter on YouTube | ResearchBuzz: Firehose
More from ResearchBuzz: Firehose
Continued thread
Update. Laws like the one in #Connecticut are under consideration in #Hawaii, #Massachusetts, and #NewJersey. Big #publishers and the #AuthorsGuild are lobbying against them.
https://www.nytimes.com/2025/07/16/books/libraries-e-books-licensing.html
From Alan Inouye (@alansinouye), former director of public policy for the American Library Association (@alalibrary): “It’s really sad [that opposition limits libraries] to what we had [in the age of print]. In effect, we’re excluding the possibility of being better in the digital world.”

The New York Times · Some States Are Pushing Back on Library E-Book Licensing Fees
Continued thread
Update. #SpringerNature has now retracted this book.
https://retractionwatch.com/2025/07/16/springer-nature-to-retract-machine-learning-book-following-retraction-watch-coverage/
Thanks to @retractionwatch for exposing it.

Retraction Watch · Springer Nature to retract machine learning book following Retraction Watch coverageA screenshot from June 26 shows the book had been accessed 3,782 times. Springer Nature is retracting a book on machine learning that had multiple references to works that do not exist, Retraction …
"#Delta moves toward eliminating set prices in favor of #AI that determines how much you personally will pay for a ticket."
https://fortune.com/2025/07/16/delta-moves-toward-eliminating-set-prices-in-favor-of-ai-that-determines-how-much-you-personally-will-pay-for-a-ticket/
PS: Lots to hate here. But suppose the model spreads to other industries. (Yes, this is sci-fi for now. But let your imagination run free.) Imagine that academic #publishers used this model to set #APCs. What would AI tools infer from your institutional affiliation (about available resources), first name (about gender), surname (about ethnicity), submitted manuscript (about guesstimated quality), and past publications (about specialization, reputation, impact)? What odd variables would it factor in, such as the number of Trump-banned words (for political protection) or the number of citations to that journal (for #JIF)? How would it use all this information? Would it lower the #APC for you, to bring you in, or raise it, to price you out?
For airlines or journals, would there be any reason to stick with the model if it didn't raise net revenues?

Fortune · Delta moves toward eliminating set prices in favor of AI that determines how much you personally will pay for a ticket